
Testing Transaction Enrichment at Scale, Part 1: Quality
Spade's engineering team highlights the automated enrichment quality tests that allow us to continuously improve our product while optimizing both match rate and match quality.


Our core product at Spade is our real-time transaction enrichment API. This service allows our customers to enrich credit card transactions, bank transfers, aggregator transactions, and more - identifying the merchant involved and providing a deep understanding of what actually happened in each interaction. We strive to continuously improve the ability of our transaction enrichment API to match on more transactions and with greater accuracy. To this end, we’ve created a series of automated Enrichment Quality Tests that run during our CI/CD pipeline. These allow us to continuously make improvements to our API while avoiding regressions in our match rate and match quality. This blog post describes how and why we run our Enrichment Quality Tests.
To start, let's define a couple key attributes of our system.
Match rate: The number of transactions where we’re able to identify the merchant involved divided by the total number of transactions we process.
Match quality: The accuracy of our matches. Was a match a false positive? Was a non-match a false negative?
We strive towards perfect match quality and a match rate of 1.0, however there are many obstacles we have to overcome in this pursuit. We need to update our data with newly created businesses, improve our enrichment engine to handle transactions that don’t follow existing patterns, expand the range of transactions we’re able to process, and cluster data points from a variety of sources into a single unified dataset. All of these challenges make the optimization of match rate and match quality a thrilling but difficult task.
Compounding this problem, traditional UI-driven products are able to collect extensive telemetry data (click-through-rates, dwell times, etc). This feedback is extremely valuable in increasing the relevance of results. As an API-based product, Spade’s enrichment API operates with a different set of metrics about quality, performance, and overall satisfaction. This challenge spurred us to proactively create our own methods for validating that our enrichments have high coverage and accuracy.
To solve this issue we created a test suite we call our Enrichment Quality Tests. These tests run during each deployment of our API and measure a series of statistics against a set of known transactions. We keep a large corpus of transactions for each of our enrichment endpoints (cards, transfers, and universal). These transactions are synthetic data which closely resembles transactions sent through our API. This allows us to preserve customer privacy while mirroring real cases we’ve observed in transaction data.
The Enrichment Quality Tests operate as a step in our CI/CD pipeline. Once new application code changes are live in our staging environment, we run a script which queries our enrichment API for each transaction. We also download a golden set of test results stored on S3. The results of the current deployment are then compared against the golden set to generate deltas. We set thresholds on certain key metrics. If the delta for a metric exceeds the threshold, then the test fails. Otherwise, if all the deltas are within acceptable thresholds the test passes and we write out the current results to S3 as our new golden copy. You can see a flowchart of this process below.
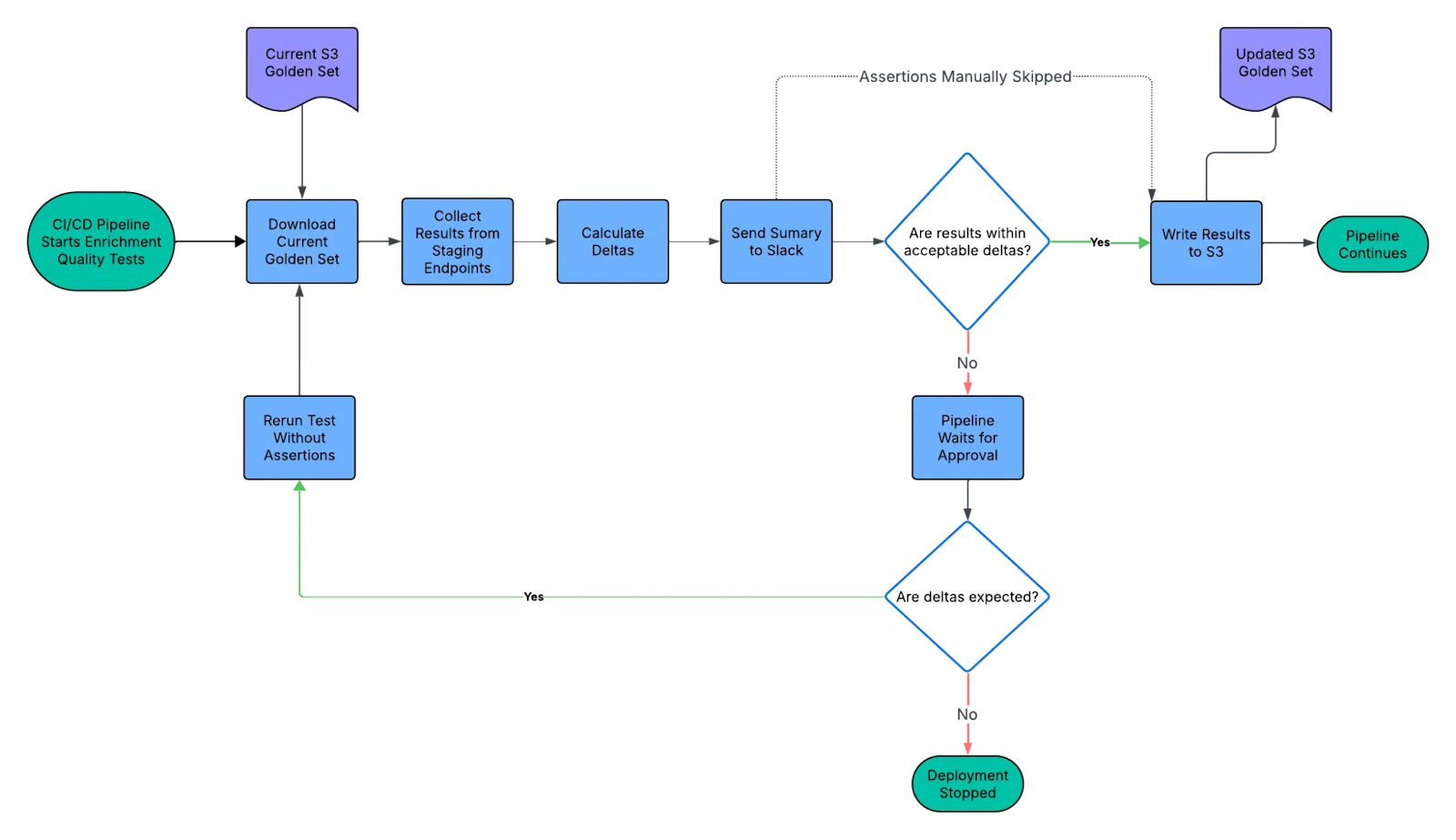
After the tests are run and the results are diffed, we automatically send them to a dedicated slack channel and notify the committer responsible for the change. If we expect the test to fail because we’re making a significant change to our enrichment process then we override the results and continue the merge. Otherwise, the merge is blocked and the committer can evaluate what went wrong. Below is a sample of what the output looks like.
| Overall Statistics | |||||
|---|---|---|---|---|---|
| Previous | Current | Relative Δ | Absolute Δ | Result | |
| Transaction Count | X ~ 100% | X ~ 100% | 0.0% | 0.0% | |
| Transaction Info Statistics | |||||
| Spending Channel = digital | X ~ 18% | X ~ 18% | 3.4% | 0.6% | + |
| Spending Channel = physical | X ~ 20% | X ~ 21% | 2.5% | 0.5% | + |
| Transaction Type = spending | X ~ 92% | X ~ 92% | 0.0% | 0.0% | |
| Third Party Statistics | |||||
| Third Parties ≥ 1 | X ~ 2% | X ~ 11% | 433.3% | 9.1% | +++++ ⚠ |
| Third Parties == 1 | X ~ 2% | X ~ 11% | 433.3% | 9.1% | +++++ ⚠ |
| Third Parties > 1 | X ~ 0% | X ~ 0% | 0.0% | 0.0% | |
| ID Count | X ~ 2% | X ~ 11% | 433.3% | 9.1% | +++++ ⚠ |
| ID Count (unique) | X ~ 0% | X ~ 2% | 400.0% | 1.6% | ++ |
| Logo Count | X ~ 2% | X ~ 11% | 433.3% | 9.1% | +++++ ⚠ |
| Logo Count (unique) | X ~ 0% | X ~ 2% | 400.0% | 1.6% | ++ |
| Website Count | X ~ 2% | X ~ 11% | 433.3% | 9.1% | +++++ ⚠ |
| Website Count (unique) | X ~ 0% | X ~ 2% | 400.0% | 1.6% | ++ |
| Name Count | X ~ 2% | X ~ 11% | 433.3% | 9.1% | +++++ ⚠ |
| Name Count (unique) | X ~ 0% | X ~ 2% | 400.0% | 1.6% | ++ |
We also enable ourselves to run the Enrichment Quality Tests locally, with options to use either the golden set of results from S3 or a local set of results. This helps us to speed up development by getting immediate feedback on how a code change will impact enrichment quality. When working with core parts of our enrichment engine, we can gain confidence that the quality of our API responses is increasing.
For example, the data above shows an increase in “rate of transfer enrichments with matched third parties”. This delta was expected based on the nature of the change that was being merged. In this case, the test output validated the behaviour we wanted to see and confirmed the effect of the code change. Had we not seen the expected positive change, the deployment process would have continued as normal so long as the delta was within the established thresholds. However, the author would have been alerted to the results and could have stopped the deployment to understand why their code wasn’t working as anticipated.
In the past, these tests have alerted us to clustering issues in our data. In one such incident, we were returning the wrong ID for an important counterparty which caused the Enrichment Quality Tests to fail during the next deployment. We were alerted by the test failure and quickly fixed the underlying data before the change went out, or customers were impacted.
We periodically update these tests as new features are added to our API or when we discover inaccuracies in our matching. We remove some less relevant data points from each test’s collection of transactions and replace them with data which would trigger a new feature or where we noticed a bad match. At the moment, the cadence for these updates is ad hoc, however we have plans to improve this by automatically generating synthetic data from user error reports to keep our datasets as fresh as possible.
The Enrichment Quality Tests are just one piece of the testing framework we use to maintain and improve our match rate and match quality. But, they are a key element in preventing regressions and allowing us to deploy with confidence. Stay tuned for part 2 of this series where we’ll dive into our testing strategy around the other key metric of our API: latency.
If the challenge of turning millions of rows of messy data into highly accurate business information (and doing it while maintaining lightning fast latencies 😉) sounds exciting to you, check out our careers page. And if you’re looking for the best solution in transaction enrichment, reach out to sales@spade.com.